ChatGPT Uninstall Rates Surge by 413%: Users Are Leaving
This is not just a simple user complaint; it marks a significant industry pathology outbreak. The core indicators in the diagnosis are alarming: In March 2026, ChatGPT’s uninstall rate skyrocketed by 413%, while the growth rate of monthly active users plummeted from 168% in January to 78% in April. This is no longer a slowdown in growth but a clear signal of users voting with their feet, driven by four structural “pathologies” in the product’s core performance.
Four Symptoms: Abnormal Indicators on the Test Results
The symptoms are not vague complaints about usability but quantifiable, reproducible issues.
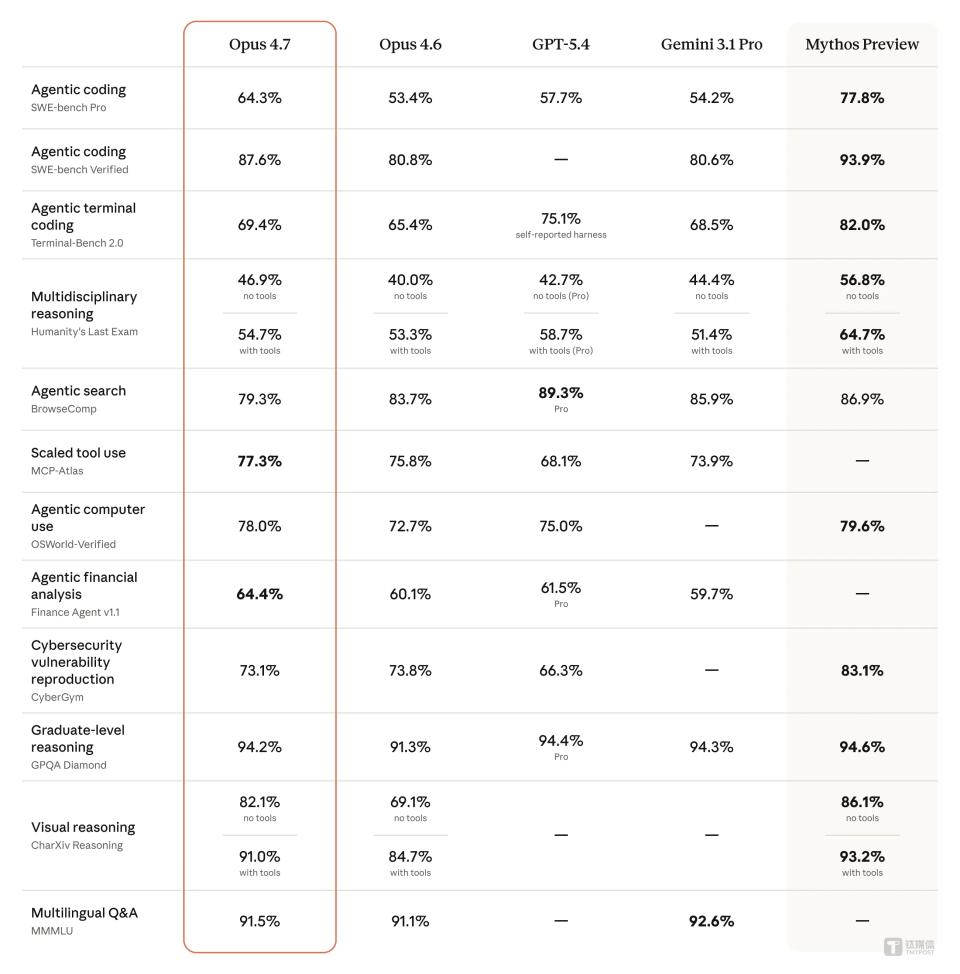
First, high hallucination rates pose a ticking time bomb in professional fields. This is not an ordinary error; it is AI confidently outputting fabricated information. In the AA-Omniscience knowledge boundary test, GPT-5.5’s hallucination rate reached 86%, while competitor Claude Opus 4.7 was only 36%.
In specialized areas, the consequences are even more severe: GPT-4 recommended nonexistent drug combinations in 37% of rare disease diagnoses. Lawyer Steven Schwartz used it to draft court documents, resulting in citations of six completely fabricated cases, nearly leading to his license being revoked. When AI’s “certainty” becomes the greatest uncertainty risk, professional users can only flee.
Second, slow response times turn “deep thinking” into an efficiency bottleneck. Users have intuitively compared and found that competitors like Gemini can provide instant answers, while ChatGPT often takes several seconds to “ponder”. The technical root lies in its use of RLVR (Reinforcement Learning with Verified Rewards) training and low-temperature beam search strategies, which aim for optimal answers at the cost of immediate interaction fluidity. In efficiency-driven scenarios, such delays are enough to deter users.
Third, degraded foundational capabilities lead to trust backlash against version iterations. User feedback indicates that the new model performs worse than earlier versions (like GPT-4o) in factual accuracy and logical coherence. The new strategy has shifted to “fuzzy fallback and inference”, resulting in a dual decline in efficiency and trust. Even its voice function has an average 2.3-second wake-up delay, leading to a mere 12% usage rate.
When updates fail to enhance the experience and instead create new pain points, user retention naturally collapses.
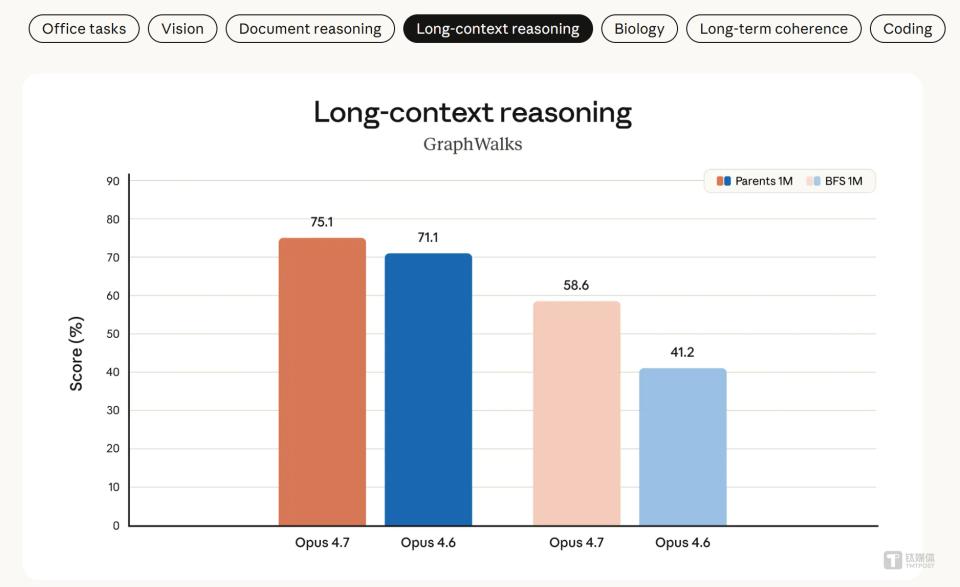
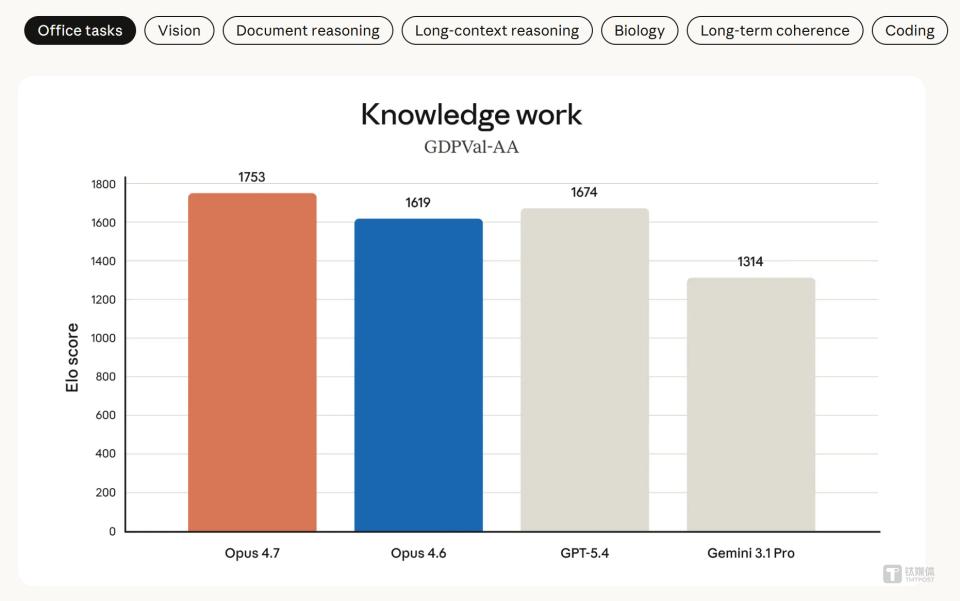
Fourth, loss of long context is the Achilles’ heel of the agent vision. OpenAI’s promoted concept of “agents” is centered on handling complex, multi-step long tasks. However, ChatGPT struggles with tasks requiring ultra-long context memory. In the OfficeQA Pro evaluation (analyzing 90,000 pages of documents), it scored only 51.1%, while Claude Opus 4.7 achieved 80.6%, showing a clear advantage. This raises doubts about ChatGPT’s reliability in core office scenarios like financial analysis and long document processing.
Diagnosis of Causes: External Competition and Internal Bottlenecks
The external cause is clear: a superior “reference frame” has emerged. Anthropic’s Claude not only contrasts favorably against the aforementioned key performance indicators but also attracts users who have lost trust in OpenAI due to its collaboration with the Pentagon, thanks to its clear ethical boundaries (such as banning autonomous weapons). 67% of respondents support tech companies setting ethical limits, making values a crucial decision factor after technical parameters converge.
The internal cause is fatal: OpenAI is mired in multiple bottlenecks.
- The peak of technological dividends has been reached: The Scaling Law is gradually failing, and the marginal performance gains from merely stacking computational power and parameters have approached zero.
- The inherent contradiction in data and evaluation systems: High-quality training data is dwindling, and OpenAI’s own paper published in Nature points out that the current binary scoring system based on accuracy (correct answers score, incorrect or skipped answers score nothing) systematically encourages models to “guess answers” rather than “admit they don’t know”, which is one of the roots of hallucinations.
- Imbalance in business models and cost structures: The company is caught in a GPU arms race with extremely high fixed costs. Although the gross profit from API calls may be high, the exorbitant training costs, subsidies for free users, and R&D investments put pressure on the overall profitability model. After the release of GPT-5.5, the output token price rose to $30 per million, higher than Claude’s $25, further testing user loyalty.
Prognosis: Structural Adjustment, Not a Phase Decline
ChatGPT is facing not a short-term storm but a structural adjustment that is inevitably occurring as the industry shifts from “technological showmanship” to “practical reliability”. The prognosis can be categorized into three levels:
- Conditions for possible recovery (short-term): If OpenAI can significantly reduce hallucination rates and improve response speeds through architectural optimization (such as model hierarchical collaboration) while stabilizing core enterprise customers (who prioritize workflow integration), it can stem the bleeding. Its latest GPT-5.5 has shown a rebound in some agent task tests, indicating that its technical foundation remains strong.
- Conditions for continued deterioration (mid-term): If core issues like hallucinations remain unresolved while competitors like Claude continue to build barriers in long context and professional scenarios, high-value individual users and professional enterprises will continue to migrate. Claude’s 85% retention rate among Fortune 10 companies has already proven this trend.
- Long-term industry impact: This competition signals that the dimensions of AI industry competition have expanded from simple “model IQ” testing to a comprehensive contest of “reliability × values × cost”. The universal model’s “omnipotent” aura is fading, and contextual capabilities, deep optimization in vertical fields, and trustworthy ethical boundaries will become the new core competitiveness.
Products that cannot adapt to this shift, even if they once led the trend, may quietly exit as users vote with their feet.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.